
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 원정
- 일엽편주
- 5G
- 텐동텐야
- 환상자전거길
- 오스너예가다이얼
- network slicing
- LG TECH CONFERENCE 2023
- 원정응원단석
- V1구역
- 제주도 자전거여행
- 신해바라기 분식
- sk와이번스
- 드림라이브존
- 롯데시네마 현풍
- 제주 담스테이
- 창원nc파크
- 후기이벤트참여
- 리클라이너석
- 전복 김밥
- 담화탁주
- 직관
- 티스토리챌린지
- 술담화
- 아이오닉5
- 오블완
- 올스타전
- 프로야구
- 제주도
- SK 와이번스
- Today
- Total
개루프이득의 블로그
Keras를 이용해 MNIST dataset pre-training 시키기 본문
최근 딥러닝 관련 수업을 들으면서 tensorflow가 아닌 Keras라는 툴을 사용하게 되었다.
이번에는 Keras를 이용해서 가장 간단한 데이터셋인 MNIST에 대해 pre training 기법을 사용하는 것을 실습해 봤다.
모든 파이썬 코드는
https://github.com/KimTaeyeoun/-Study/tree/master/pre%20training%20with%20MNIST
KimTaeyeoun/-Study
Contribute to KimTaeyeoun/-Study development by creating an account on GitHub.
github.com
에 있다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
img_rows = 28
img_cols = 28
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
input_shape = (img_rows, img_cols, 1)
batch_size = 256
num_classes = 10
epochs = 12
y_pretrain = y_train[:59000]
y_training = y_train[59000:]
x_pretrain = x_train[:59000]
x_training = x_train[59000:]
|
일단은 Keras를 통해 MNIST 데이터셋을 불러오고, 총 60,000개의 데이터 중에 59,000개를 pretraing, 1,000개를 training 데이터로 이용한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
def build_model():
model = models.Sequential()
model.compile(loss='categorical_crossentropy',optimizer=optimizers.RMSprop(lr=1e-5),metrics=['acc'])
model.summary()
return model
model = build_model()
|
Keras는 딥러닝 모델을 만드는 것이 상당히 직관적인 편이다. model.add()의 명령어로 자신이 원하는 layer를 순서대로 더해주면 된다. 나는 간단한 CNN 구조를 만들어주었고, 중간에 overfitting 문제를 조금이나마 해결하기 위해 dropout layer도 추가해 주었다.
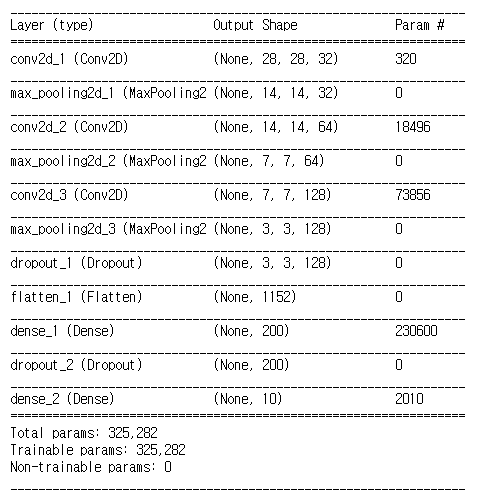
또한, Keras에서는 모델의 구조를 한 번에 확인할 수 있는 명령어도 지원을 한다. model.summary()라는 명령어를 입력하면 위의 그림과 같이 내가 설계한 네트워크의 구조를 보기 좋게 출력해준다.
|
1
|
hist = model.fit(x_pretrain, y_pretrain, batch_size=batch_size, epochs=epochs, validation_data=(x_test, y_test))
|
이제, 위의 명령어로 pretaining dataset에 대해 학습을 시켜준다. batch size는 256, epoch은 25에폭을 학습시켜 주었다.
|
1
2
3
4
5
6
7
8
9
|
model.save_weights("CNN.h5")
model_json = model.to_json()
score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
|
학습이 완료되면, 이 모델은 pre trained model로 사용될 것이기 때문에, 저장을 해준다. 나중에 parameter를 freezing 시키기 위해, 모델의 구조는 json 파일로, weight는 h5파일로 각각 저장을 해준다. 그리고 pre trained 된 모델의 성능을 확인해본 결과,
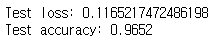
위와 같이 약 96.52%정도의 성능이 나왔다. 사실, MNIST 데이터셋의 경우는, 지금과 같은 CNN 모델에 adam optimizer를 쓰면 5 epoch 이내에 거의 99%의 정확도에 도달한다. 하지만, 이번 프로젝트를 위해서는 그보다는 적당히 96~97% 정도의 정확도를 갖는 모델으로 비교를 하는 것이 좋을 것 같다고 생각하여, 조금 더 수렴속도가 느린 optimizer를 이용했다.
다음으로는 이제 이 trained된 model에 small data를 이용해 학습을 시켜본다.
|
1
2
3
4
5
6
7
8
9
|
loaded_model_json = json_file.read()
json_file.close()
model2 = model_from_json(loaded_model_json)
model2.load_weights("CNN.h5")
model2.compile(loss='categorical_crossentropy',optimizer=optimizers.RMSprop(lr=1e-5),metrics=['acc'])
hist2 = model2.fit(x_training, y_training, batch_size=256, epochs=100, validation_data=(x_test, y_test))
|
위와같이 json과 h5 파일에서 모델을 불러오고, 이 위에 그냥 다시 small dataset으로 학습을 시킨다. 사실 이 경우는 pre-trained 된 데이터를 이용한다기 보다는, 그냥 이전에 학습된 모델을 저장하고, 다시 불러와서 다른 데이터를 추가해줘서 학습해주는 경우에 더 가깝다고 볼 수 있을 것 같다.
이 경우에는 데이터 양이 매우 적어서 금방 학습이 되기 때문에 100 epoch을 학습시켜봤다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
score = model2.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
fig, acc_ax = plt.subplots()
acc_ax.set_ylabel('accuracy')
acc_ax.set_xlabel('epochs')
|
그리고 이 모델을 위와 같은 코드로 성능을 평가하고, 그래프를 그려봤다.
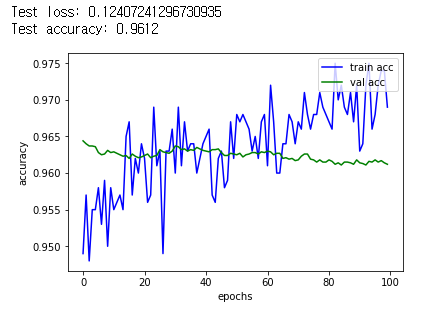
그 결과, 정확도가 약간 떨어지면서, small dataset인 training 데이터셋에 과적합 되는 경향을 볼 수 있었다.
다음으로는, pre training에서 사용하는 fine-tunning이라는 기법으로, CNN의 feature extraction 부분은 pre trained된 모델에서 parameter를 더 이상 학습시키지 않고, classifier 부분만 미세하게 학습을 시키는 것이다.
|
1
2
3
4
5
6
7
8
9
10
11
12
|
loaded_model_json = json_file.read()
json_file.close()
model3 = model_from_json(loaded_model_json)
model3.load_weights("CNN2.h5")
layer.trainable = False
model3.summary()
|
그래서 다시 한 번 모델을 불러오고, densely connected layer 부분만 학습이 되도록 나머지 layer들은 모두 freeze를 시켜줬다. 이 모델의 구조를 다시 한 번 확인을 해보면,
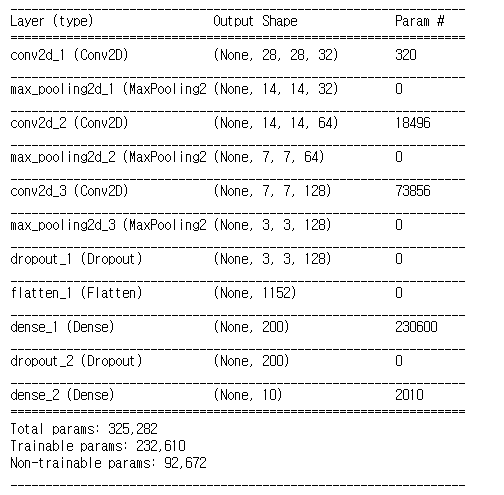
처음 pre training 모델과 같은 구조이지만, Non-trainable params가 생긴 것을 알 수 있다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
model3.compile(loss='categorical_crossentropy', optimizer=optimizers.RMSprop(lr=1e-5), metrics=['accuracy'])
hist3 = model3.fit(x_training, y_training, batch_size=batch_size, epochs=100, validation_data=(x_test, y_test))
score = model3.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
fig, acc_ax = plt.subplots()
acc_ax.set_ylabel('accuracy')
acc_ax.set_xlabel('epochs')
|
앞에서와 똑같이 코드를 돌리고, 성능 테스트를 해봤다.
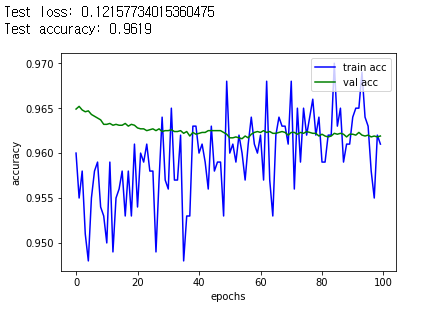
뭔가 freezing을 시켰다고 눈에 띄는 차이가 생긴 것 같지는 않다.... 그도 그럴 것이 정말 실습을 위한 프로젝트라, 원래 같은 dataset이었던 data들을 임의로 나눠서 한 것이라, 이걸로 뭐 큰 차이를 보기는 힘들 것 같다.
다만, 그냥 이 small dataset으로 처음부터 학습시키는 것과 비교하는 것은 의미가 있을듯 하다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
model4 = build_model()
hist4 = model4.fit(x_training, y_training, batch_size=batch_size, epochs=100, validation_data=(x_test, y_test))
score = model4.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
fig, acc_ax = plt.subplots()
acc_ax.set_ylabel('accuracy')
acc_ax.set_xlabel('epochs')
|
그래서 간단한 코드로, pre training model과 같은 구조를 만든 후, 처음부터 학습을 시켜줘 봤다.
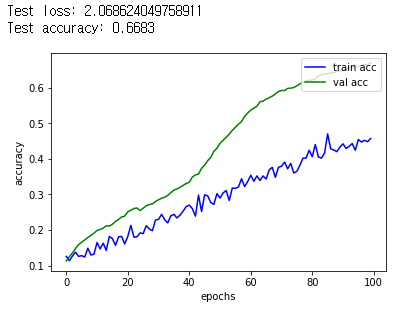
확실히 이거보다는 pre trained model을 이용하는 것이 빠르다는 것을 알 수 있었다.
추가적으로, pre trained를 가져와서 학습시킨 모델을 400에폭 정도 더 돌려봤는데 역시 큰 차이 없었고, small dataset의 optimizer를 adam으로 바꿔서 해보니 더욱 빠르게 overfitting되는 결과만 가져온 것을 확인할 수 있었다. (이는 궁금하면 깃허브의 코드를 통해 확인해보자.)
이번 프로젝트로 pre training의 fine tunning의 장점을 확실히 확인할 수는 없었지만, 그 기법을 사용하는 방법을 실제로 짜보는 기회가 된 것 같다.
'전공 공부' 카테고리의 다른 글
| 다양한 적분 방법 : 삼각치환법과 부분 분수를 이용한 적분 (0) | 2020.03.31 |
|---|---|
| 함수의 극한 정의 : 입실론-델타 논법 (4) | 2020.03.24 |
| Delay jitter란 무엇이고, 왜 필요할까 (2) | 2019.11.14 |
| Edge Computing이란? (0) | 2019.08.25 |
| SDN과 NFV의 차이 (0) | 2019.08.19 |



