연합 학습 간단한 예제로 공부해보기
대학원때부터 관심이 있던 부분 중에 하나였다.
호기심의 시작은 연합학습 (Federated learning) 과 분산학습 (Distributed learning)의 차이가 무엇일까였다.
개인적으로 나에게는 어찌보면 너무 명확하게 달라보이는 개념이기도 하고, 반대로 구현상의 큰 차이를 잘 모르겠는 개념이기도 했다.
이번 글에서는 연합학습과 분산학습을 비교해보고, Chat GPT의 도움을 받은 간단한 연합학습 예제문제를 풀어보려고 한다.
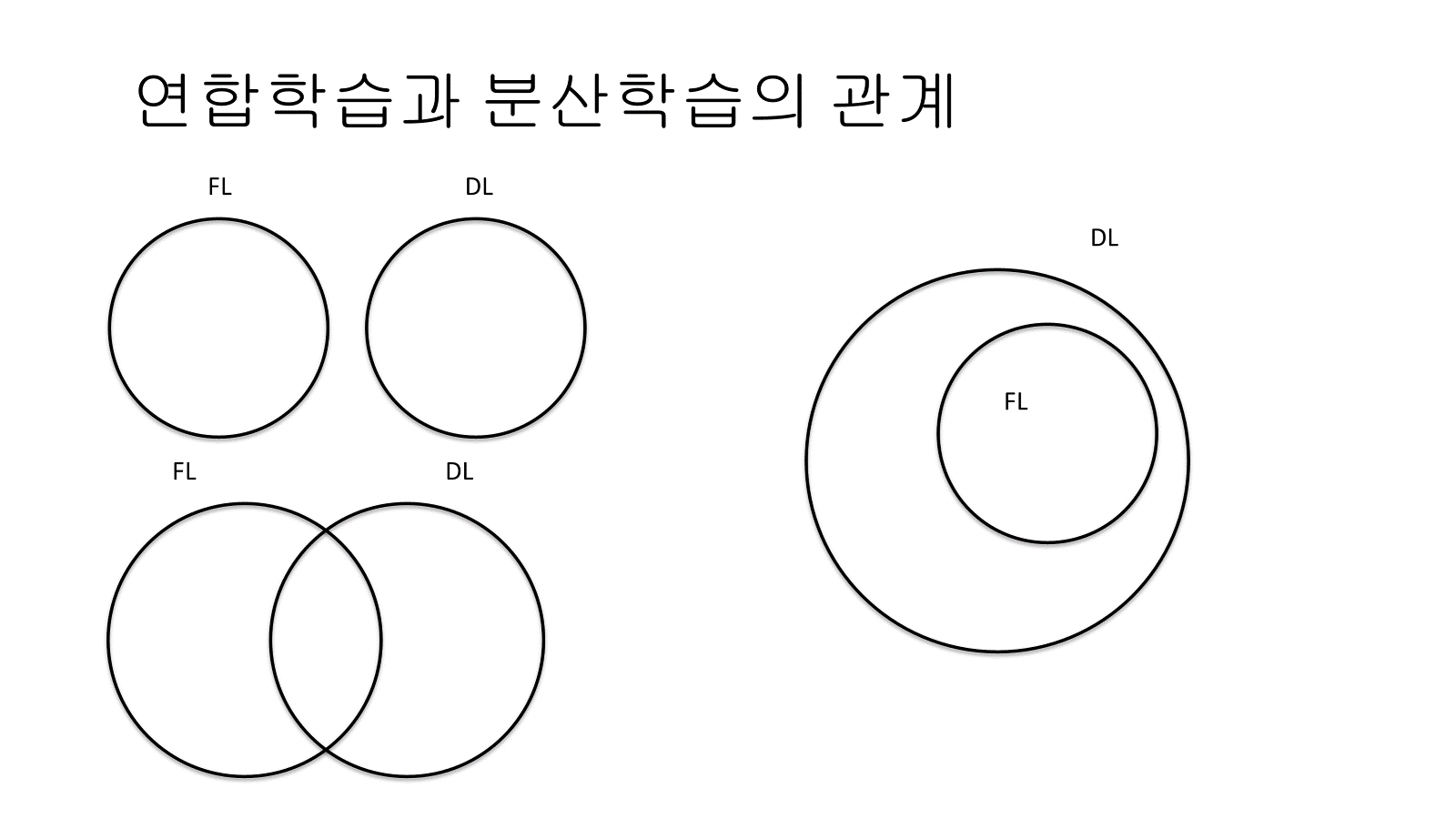
연합학습과 분산학습을 어떻게 이해할 수 있을까?
난 처음에 조금 공부를 했을 때는, 둘이 아예 별도의 개념이라는 생각을 했다.
그러다가 FL이 DL에 포함이 되는 개념인가? 라고 생각을 했다가,
마지막에는 어느 정도 공통부분이 존재는 하지만 포함관계는 아니다 라는 결론을 내렸다.
가장 직관적인 차이점은 데이터의 이동 여부이다. 연합학습의 경우는 데이터는 중앙 모델로 이동하지 않고, 모델 파라미터만 업데이트를 해주는 개념이다. 이때문에, 연합학습은 늘 개인정보 보호에 장점이 있다는 말이 따라다닌다. 반대로, 분산학습은 연합학습처럼 모델 파라미터만 공유를 할 수도 있지만, 기본적으로는 데이터까지 분산된 서버에 보내주면서, 데이터와 연산을 병렬처리하는 것을 목적으로 한다.
즉, 내가 이해하기로는 분산학습은 하나의 큰 모델을 학습시키는 것이 목적인데, 이를 위해서 높은 컴퓨팅 자원이 필요하니 데이터와 연산을 여러 노드에 분산해서 처리해주는 개념이고, 연합학습은 물론, global 모델의 최적화가 목적이기는 하지만, 주기적 통신을 통한 업데이트를 통해서 client 모델들 각자의 성능 향상도 가져오는 것을 목적으로 하는 것 이라고 이해했다.
일반적으로는 연합학습을 위해서는 global과 client 가 같은 모델을 공유해야하게 되는데, 이는 네트워크 엣지에 있는 client에게는 부담스러운 환경이 될 수도 있기 때문에, 모델 양자화, 가지치기 등의 기법을 통한 에너지 절약 기술들이 연구가 되고 있다고 한다.
이러한 연합학습을 간단한 코드로 실습해봤다. (엄밀하게 보면, FL과 DL의 교집합에 해당되는 부분에 대한 실습이라고 볼 수 있을 것 같다.)
처음에 Chat GPT 4o에게 예제 코드를 짜달라고 했더니, 내가 원하는 형식의 예제도 아니었고, client 모델들을 파라미터를 업데이트 받는 global 모델의 파라미터도 제대로 계산이 되지 않았다.
그래서 계속 프롬포팅을 하면서 코드 수정을 했고, F-MNIST 데이터를 기반으로 학습을 하며, 연합학습 client 는 5개가 있다고 가정을 하고, 총 7번의 round를 돌면서, 한 번의 round 가 끝나면 client 들의 모델 파라미터를 받아와서 global parameter를 업데이트 시켜주고, 다음 round에서는 그 업데이트된 global parameter 들을 다시 client 들에게 보내줘서 클라이언트들이 그 global parameter로부터 학습을 하도록 설계해줬다.
https://github.com/TaeyeounKim96/FL_example/blob/main/FL%20%EC%8B%A4%EC%8A%B5.ipynb
FL_example/FL 실습.ipynb at main · TaeyeounKim96/FL_example
Contribute to TaeyeounKim96/FL_example development by creating an account on GitHub.
github.com
참고로 코드는 여기서 확인할 수 있긴 하다.
import numpy as np
import tensorflow as tf
from tensorflow.keras.datasets import fashion_mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten, Conv2D, MaxPooling2D
from tensorflow.keras.optimizers import SGD
import matplotlib.pyplot as plt
# MNIST Fashion 데이터셋 로드
(x_train, y_train), (x_test, y_test) = fashion_mnist.load_data()일단은 필요한 라이브러리 들은 모두 install이 되어 있다는 가정하여, 코드에 필요한 라이브러리들을 import 해주고, fashion_mnist 데이터셋을 불러온다.
# 데이터 전처리
x_train = x_train.astype('float32') / 255.0
x_test = x_test.astype('float32') / 255.0
x_train = np.expand_dims(x_train, -1) # 채널 차원 추가
x_test = np.expand_dims(x_test, -1) # 채널 차원 추가
y_train = tf.keras.utils.to_categorical(y_train, 10)
y_test = tf.keras.utils.to_categorical(y_test, 10)
# MNIST Fashion 클래스 이름
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
# 각 라벨별 데이터 예시 시각화
num_classes = len(class_names)
plt.figure(figsize=(15, 6))
for i in range(num_classes):
idxs = np.where(y_train[:, i] == 1)[0]
idx = np.random.choice(idxs)
plt.subplot(2, num_classes // 2, i + 1)
plt.imshow(x_train[idx].squeeze(), cmap='gray')
plt.title(class_names[i])
plt.axis('off')
plt.show()학습을 위한 데이터 전처리를 해주는 과정이다. 데이터의 예시들을 print 해서 확인해보면, 아래와 같은 클래스로 이루어진 파일들이라는 것을 확인 할 수 있다.

# 연합학습을 위한 데이터 분할
num_clients = 5
client_data_size = len(x_train) // num_clients
client_data = [(x_train[i * client_data_size: (i + 1) * client_data_size],
y_train[i * client_data_size: (i + 1) * client_data_size])
for i in range(num_clients)]
# 모델 생성 함수
def create_model():
model = Sequential([
Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
MaxPooling2D((2, 2)),
Conv2D(64, (3, 3), activation='relu'),
MaxPooling2D((2, 2)),
Flatten(),
Dense(128, activation='relu'),
Dense(10, activation='softmax')
])
model.compile(optimizer=SGD(), loss='categorical_crossentropy', metrics=['accuracy'])
return model
# 모델 생성
model = create_model()
model.summary()이제 연합학습을 위해 clinet 의 수 만큼 데이터를 분할해주고, 예제에 활용할 모델 활용 함수를 정의한다.
나는 AI에 대해서 관심은 많지만, 학습 방법론이나 학습이 이루어지는 구조에 대해서 관심이 많지, 모델 자체 개발에 대해서는 큰 관심은 없다.
그래서 모델은 그냥 전지전능한 GPT가 추천해준 모델을 그대로 활용했다. 그 모델을 확인해보면, 아래와 같은 모델을 쓴다고 한다.

이제 학습을 위한 함수들을 정의하는 부분이다.
# 클라이언트 모델 초기화
def initialize_client_models(num_clients, global_weights=None):
client_models = []
for _ in range(num_clients):
model = create_model()
if global_weights is not None:
model.set_weights(global_weights) # 모든 클라이언트 모델에 동일한 글로벌 가중치 설정
client_models.append(model)
return client_models
# FedAvg로 글로벌 모델 업데이트 함수
def federated_averaging(client_models, client_data):
global_model = create_model()
# 클라이언트 데이터 샘플 수를 기준으로 가중치 계산
num_samples = [data[0].shape[0] for data in client_data]
total_samples = sum(num_samples)
client_weights = [samples / total_samples for samples in num_samples]
# 각 클라이언트의 가중치를 평균화
model_weights = [model.get_weights() for model in client_models]
average_weights = []
for weights_list in zip(*model_weights):
average_weights.append(np.average(weights_list, axis=0, weights=client_weights))
global_model.set_weights(average_weights)
return global_model
# 각 클라이언트 모델 학습 함수
def train_client_model(client_data, model, epochs=5, batch_size=32):
history = model.fit(client_data[0], client_data[1], epochs=epochs, batch_size=batch_size, verbose=1)
return history
# 연합 학습 반복 함수
def federated_learning(num_rounds, num_clients, client_data):
# 초기 글로벌 모델 설정
global_model = create_model()
global_model_accuracies = []
for round in range(num_rounds):
print(f"Round {round + 1}/{num_rounds}")
# 클라이언트 모델 초기화
client_models = initialize_client_models(num_clients, global_weights=global_model.get_weights())
# 클라이언트 모델 학습
for i in range(num_clients):
print(f"Training client model {i + 1}...")
train_client_model(client_data[i], client_models[i])
# FedAvg로 글로벌 모델 생성
global_model = federated_averaging(client_models, client_data)
# 글로벌 모델 평가
test_loss, test_acc = global_model.evaluate(x_test, y_test, verbose=0)
global_model_accuracies.append(test_acc * 100)
print(f'Global model test accuracy: {test_acc * 100:.2f}%')
# 학습 상황 및 최종 결과 그래프
client_accuracies = [model.evaluate(x_test, y_test, verbose=0)[1] for model in client_models]
plt.figure(figsize=(10, 6))
plt.plot(range(num_clients), client_accuracies, 'bo-', label='Client Models')
plt.axhline(y=test_acc, color='r', linestyle='-', label='Global Model')
plt.xlabel('Client')
plt.ylabel('Accuracy')
plt.title(f'Client Models vs Global Model Accuracy (Round {round + 1})')
plt.legend()
plt.show()
# 특정 테스트 인덱스를 선택하여 예측 결과 시각화
num_samples = x_test.shape[0]
test_index = np.random.randint(num_samples)
plt.figure(figsize=(12, 6))
for i in range(num_clients):
plt.subplot(2, num_clients, i + 1)
plt.imshow(x_test[test_index].squeeze(), cmap='gray')
client_prediction = np.argmax(client_models[i].predict(x_test[test_index:test_index+1]))
true_label = np.argmax(y_test[test_index])
plt.title(f"Client {i+1}\nPred: {client_prediction}\nTrue: {true_label}")
plt.axis('off')
plt.subplot(2, num_clients, num_clients + 1)
plt.imshow(x_test[test_index].squeeze(), cmap='gray')
global_prediction = np.argmax(global_model.predict(x_test[test_index:test_index+1]))
true_label = np.argmax(y_test[test_index])
plt.title(f"Global Model\nPred: {global_prediction}\nTrue: {true_label}")
plt.axis('off')
plt.show()
return global_model, global_model_accuracies학습을 할 때, 클라이언트 모델들이 너무 반대방향으로 학습이 되면, 파라미터 업데이트가 제대로 안 될 수도 있기 때문에, 클라이언트 초기화를 할 때, 초기 모델들의 랜덤 웨이트를 같은 값으로 맞춰주기 위한 함수를 정의해줬다.
그리고 글로벌 모델 업데이트 함수의 경우는, 클라이언트들의 모델 파라미터를 데이터 샘플 수 기준으로 가중 평균을 계산해주는 식으로 정의해줬다. 이 글로벌 파라미터 업데이트는, 가장 기본적인 방법이 이렇게 모든 파라미터들을 받아서 평균값을 쓰는 것 이라고 한다. 물론 더 고도화된 기법들도 있기는 한 것 같다.
다음으로는 tensorflow로 간단하게 구현해 줄 수 있는 클라이언트 모델 학습 함수를 구현해주었다.
그리고, 이제 라운드를 돌면서 global 모델과 client들을 상호 업데이트해주는 부분을 구현하면서, 중간 중간 확인할 만한 그래프를 뽑아주는 코드들도 추가해줬다. 여기서, 상호간의 업데이트가 되도록 하기 위해서, 각 라운드가 돌 때마다 client model들의 파라미터를 global model의 파라미터들로 초기화를 해준다.
# 연합 학습 수행
num_rounds = 7
global_model, global_model_accuracies = federated_learning(num_rounds, num_clients, client_data)
# 최종 글로벌 모델 평가
test_loss, test_acc = global_model.evaluate(x_test, y_test, verbose=0)
print(f'Final global model test accuracy: {test_acc * 100:.2f}%')
# 라운드에 따른 글로벌 모델 정확도 변화 그래프
plt.figure(figsize=(10, 6))
plt.plot(range(1, num_rounds + 1), global_model_accuracies, 'r-o', label='Global Model Accuracy')
plt.xlabel('Round')
plt.ylabel('Accuracy (%)')
plt.title('Global Model Accuracy Over Rounds')
plt.legend()
plt.show()이제 마지막 실행을 위한 코드블럭이다.
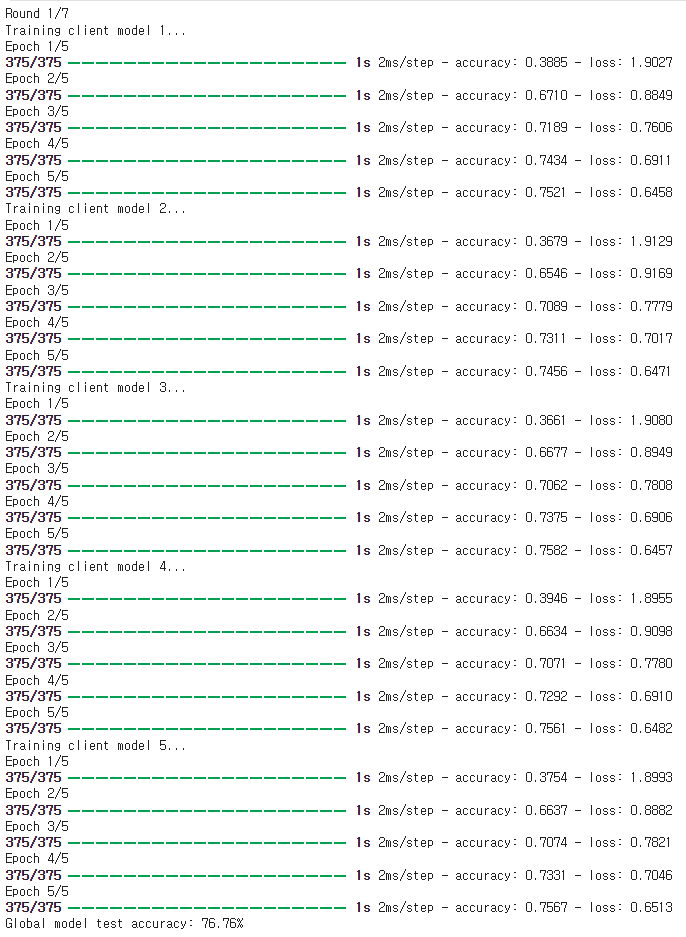
각 라운드 별로, 정의 된 에폭 수 만큼 각각 클라이언트들이 학습되는 것을 이렇게 확인 할 수 있으며,
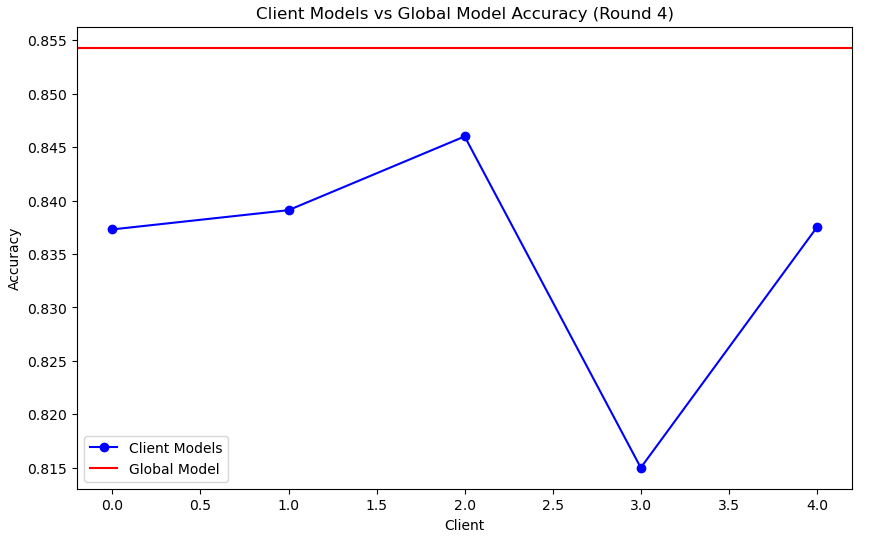
라운드가 끝날 때 마다 이렇게 각 라운드 별 client 와 global 모델의 test 정확도를 비교해준다.
7라운드를 돌린 결과를 글로벌 모델만 대표로 추세를 확인해보면,
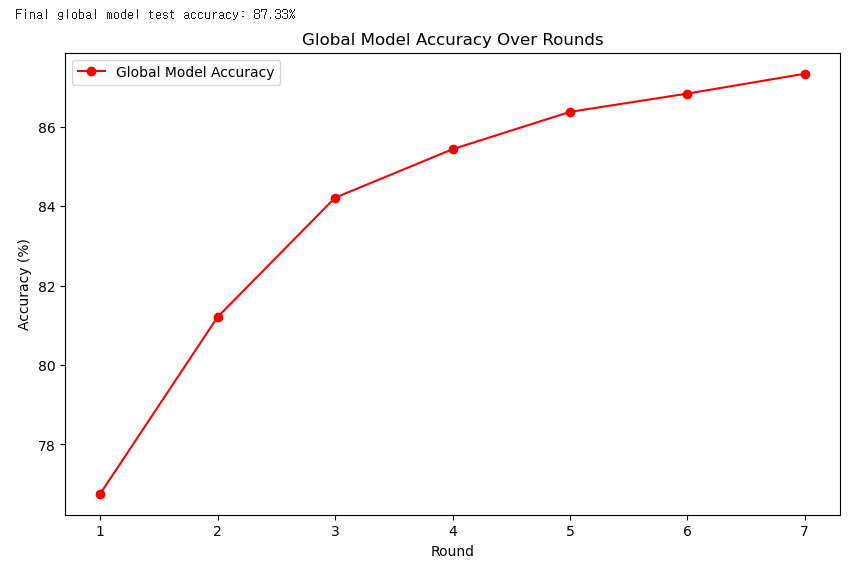
이렇게 그래도 대강 보면 어느 정도 학습이 잘 진행되는 것을 확인 할 수 있다. 물론, client 들도 이와 비슷하게 라운드를 거칠수록 조금씩 성능이 좋아지는 것이 확인되었다.
솔직히 이 모델에서는 global은 학습은 하지 않고, client 들의 파라미터 평균만 구해서 업데이트를 해주는데 학습이 되는 것 처럼 성능이 나오는 것을 보니 신기하기는 했다.
정말 기초적인 예시라서, 파라미터 전송 시의 에러나 채널 환경 이런건 전혀 고려가 안 된 예시이긴 했지만, 그래도 직접 구현을 해보니 재미도 있고, 이해도 잘 되는 것 같았다.
사실 생성형 AI 모델이 없으면, 이런걸 해보는 것도 꽤나 시간이 오래 걸리고 많은 노력을 투자해야하는 일인데, 개인적인 공부를 하기에는 정말 좋은 시대가 된 것 같다.
거기에대가 Gen-AI 모델들이 적당히 멍청(?)해서 어느 정도 개념을 이해하고, 내가 원하는 방향으로 예제 코드를 만들어주도록 프롬포팅을 해야하다보니 공부를 하기에는 뭔가 오히려 더 좋은 환경 같기도 하다. (참고로 이런 원하는 결과를 확인하기 위해 약 1시간 정도 Chat GPT 와 싸우면서 프롬포팅 작업을 했다...ㅎㅎ)
대학원을 졸업한 내가 왜 뜬금없이 연합학습 AI 스터디 포스팅을 올릴까? 판단은 각자의 몫이다.
확실한 건 여기에 공유하는 내용은 당장 내 업무 내용은 아니긴 하다ㅎㅎ