DQN (Deep Q-Network)과 DDPG (Deep Deterministic Policy Gradient)
이전 게시물
https://openloopgain.tistory.com/123
강화 학습 (Reinforcement Learning) 개념 정리
학위를 마무리하기 시작하면서, 내가 application 으로 사용했던 기술들에 대한 개념 정리를 함께 진행하고 있다. 그러면서 내가 대학원 1, 2년차 때 정리를 했던 cloud/edge computing, SDN/NFV, network slicing
openloopgain.tistory.com
에 이어서, 예고한대로 DQN과 DDPG에 대해 간단히 정리를 해봤다.
강화학습 알고리즘에서 아마 가장 많이 언급이 되고 들어봤을 DQN과, policy gradient 기반의 가장 대표적인 모델인 DDPG에 대해서 각각의 특징, 장/단점을 늘 하이레벨에서 비교를 해본다.
DDPG를 개념적으로 이야기하면 아래 그림과 같이 DQN과 policy gradient method를 합친 개념이라고 할 수 있다.
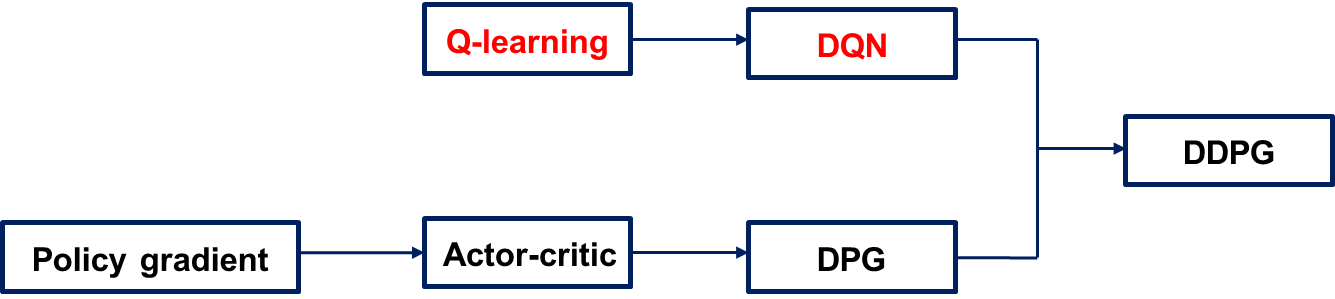
그렇다면, DDPG에 대한 이야기는 조금 뒤로 미뤄두고, 일단은 DQN이 무엇인지에 대해서 먼저 살펴보자.
강화학습의 기본이 되는 MDP의 수식적인 디테일을 최대한 생략하고, 하이레벨에서만 이야기를 하면, DQN은 일단 Q-learning에 기반을 두고 있다. 여기서 Q란, 현재 상태에서 취한 행동 보상에 대한 quality를 이야기하며, 보통은 이 Q가 action과 state에 대한 table로 표현이 된다. 즉, action과 state의 크기가 커질수록 이 table을 실제로 구현하고 학습시키는 것에 어려움이 생기게 된다.
여기서, 그렇다면 이 복잡한 Q-table을 인공신경망으로 근사를 시켜보자는 것이 DQN의 핵심 아이디어가 된다. 요즘에는 DQN 구조에서도 성능 향상을 시키거나 수렴속도를 빠르게 하기 위해서 다양한 technical한 skill들이 제안이 되고 있지만, 일반적으로 DQN은 Q-learning에 아래 3가지를 더한 개념을 이야기한다.
1. Neural network
가장 첫 번째 아이디어로, Q-table을 deep neural network (DNN)으로 비선형 근사를 시켜서 high dimensional observation 이 가능하게 한다. 이 DNN으로는 가장 간단하게는 fully connected layer들이 사용이 될 수도 있고, 학습시키고자 하는 state와 action의 특징에 따라서 CNN, RNN, LSTM 등이 사용이 될 수도 있다. 이전 포스팅에서 언급을 했듯이, 강화학습은 이러한 인공신경망 구조를 제안하기 위한 연구가 아니라, 이런 모델들을 기반으로 하는 학습의 방법론이라는 것을 다시 한 번 리마인드 한다.
2. Replay buffer
강화학습은 기본적으로 현재 state와 선택된 action이 바로 다음의 state에 영향을 미치는 Markov decision property를 따른다. 하지만, 비선형 근사된 DNN을 학습시키기 위해서는, 인공신경망에서는 대부분 각 데이터들이 서로 correlation이 없는 independent identically distributed (i.d.d.) data를 가정해서 학습을 해주기 때문에, 이 부분을 위한 작업이 필요하다. 이를 위해서 replay buffer에 일반적으로는 현재 state, 선택된 action, 다음 state에 대한 정보들을 저장해놓고, 일정 주기로 정해진 batch size 만큼 이 buffer에 저장된 data들을 sampling을 해서 학습을 해주게 된다. 이를 통해서 무작위로 선택이 되는 sample들의 correlation을 깨서, off policy training을 가능하게 해준다.
3. Target network
DQN은 주어진 state에서 최적의 action을 뽑아주기 위해 결국 input state에 대한 action을 선택해주는 Q network를 업데이트하면서 최적으로 학습을 시키는 것이 목표이다. Q network를 학습하기 위해서는 현재 network에 대해서 loss function을 계산해주고, 이 loss를 바탕으로 Q network를 업데이트 해줘야하는데, 실제 구현에서는 이 loss function을 계산해주기 위한 true global optimum의 Q network를 알지 못한다. 그래서 보통은 이 목표로 하는 Q network도 같이 학습을 시키면서 업데이트를 해주는데, 상식적으로, 우리가 Q network를 학습을 시키면서 목표로 하는 network도 계속 같이 업데이트가 된다면 학습이 잘 되기가 힘들 것이다. 이를 위해서 Target network라는 또 하나의 목표로 하는 Q network를 정의해주고, 이 Target Q는 매번 학습을 할 때마다 업데이트를 해주는 것이 아니라 조금 더 긴 주기로 업데이트가 되도록 해준다.
예를 들어 한 번의 에피소드가 끝날 때마다 replay buffer에서 sampling을 해서 Q network를 학습을 한다고 하면, target network는 업데이트 해주지 않고 유지하다가 10번의 에피소드가 끝났을 때, 그 때의 Q network로 업데이트를 해주는 방식으로 구현이 된다. 이러한 Target network는 learning stability를 올려주는 효과가 있다.
그렇다면, 이 DQN의 한계는 무엇이 있을까?
DQN의 구현이나 수식적 디테일로 들어가게 되면, Q를 업데이트 하거나 policy를 결정하는 과정에서 Q network에서 최댓값을 선택해주는 max() 함수가 포함이 된다. 이 부분에서 대부분의 DQN은 discrete한 action space를 가정하게 된다. 물론 개인적인 의견으로는 DQN으로 continuous나, 이에 가까운 action space를 구현하지 못할 것은 없다고 본다. 하지만, 이러한 부분들을 계산해주기 위해서는 continuous domain에서는 결국 한 번 네트워크를 업데이트하거나 policy를 결정할 때마다 최적화 문제를 풀어주는 꼴이 되기 때문에 straight forwardly applied되기 힘들며, action의 space와 dimension이 커져도 구현에 어려움이 생기게 된다는 한계가 있다.
DQN의 특징과 한계점을 알아봤으니, 이제 다시 DDPG로 넘어와보자.
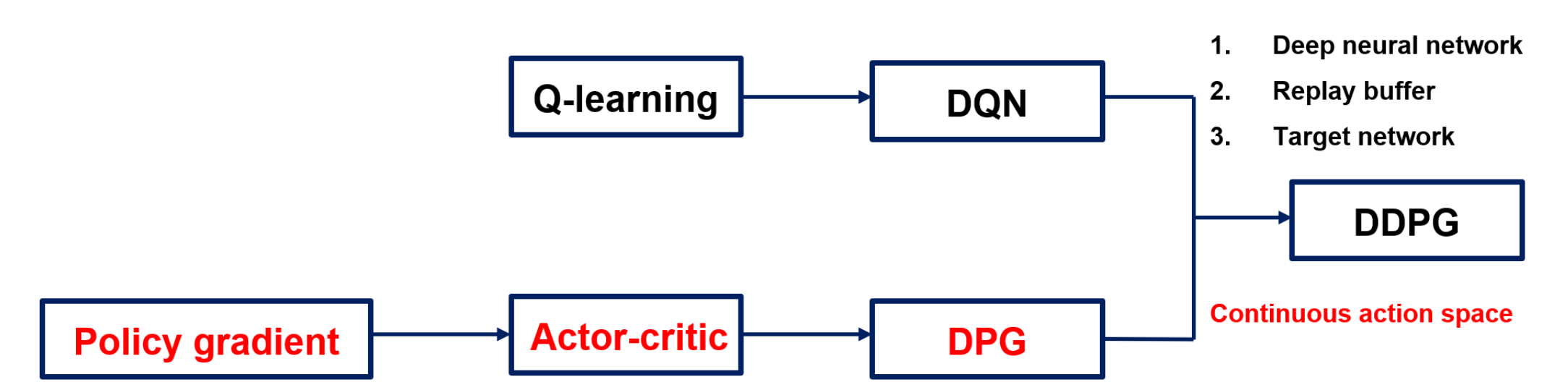
DDPG는 결국 앞서 언급한 DQN의 좋은 특징들 3가지에 policy gradient의 장점을 더한 개념이다.
그럼 성급하게 DDPG부터 이야기하기 전에, 그 바탕이 되는 개념들에 대해서 차근차근 정리를 해보자.
Policy gradient (REINFORCE)
우리에게는 REINFORCE 알고리즘으로 많이 알려진 방법으로, policy gradient는 Q 기반이 아닌 주어진 state에 대한 policy (정책)을 직접적으로 학습을 시키고자 하는 시도이다. 이를 위해 stochastic policy가 학습이 되며, 이는 다른 말로 하면, output 자체가 policy에 따른 확률이 된다는 것이다. 여기서 눈치 빠른 사람들은 알았겠지만, output이 policy에 대한 확률이 되고, 이 기반으로 soft decision을 한다면, 모델링에 따라서 충분히 continous한 action space에서의 학습이 가능하게 된다!
Actor-critic
policy를 학습시키기 위해 두 개의 네트워크를 상호학습시키는 방법으로, 내가 느끼기에는 기계학습의 GAN과 비슷한 느낌이다. Actor는 policy network에 의해 action distribution을 출력하는 network이며, 이 네트워크는 critic에 의해 업데이트 된다. Critic은 actor의 action을 평가하기 위한 네트워크이다. 그래서 output의 차원은 actor의 action dimension과 같게 설계가 된다.
DPG (Deterministic Policy Gradient)
Actor-critic을 실제로 구현하기 위해 제안된 개념 같은 느낌으로, actor의 policy를 deterministic policy로 모델링을 해준다. policy가 항상 확률 분포로 나오고, 거기에 대해 학습을 시키는 것에는 어려움이 있기 때문에, 이를 deterministic하게 제안해주는 방법이라고 할 수 있다.
DDPG
DDPG는 결국 이 continuous한 action space를 특징으로 하는 DPG에 DQN의 3가지 특징들을 합친 개념으로, DQ-learning에 continuous action space를 접목했다고 할 수 있다.
마지막으로, DQN과 DDPG를 비교하면,
DQN의 경우, 간단한 모델에서 discrete하고, 제한적인 action space에서는 안정적인 학습이 가능하다는 특징이 있다.
반대로, DDPG는 continuous한 action space까지 확장이 가능하지만, actor와 critic의 network를 모두 함께 학습/수렴시켜야하기 때문에 DQN과 비교하면 수렴성에 어려움이 있을 수 있다.
그래서 어떻게 보면 DDPG가 조금 더 advanced된 기술이라고 할 수 있지만, DQN으로 충분히 풀어줄 수 있는 문제라면? 굳이 DDPG까지 쓸 필요는 없다고 할 수 있을 것 같다.